Going Reactive: A Primer On Reactive Programming
1st January 2015If you've never come across the term "reactive programming" before, or have never heard the word "reactive" mentioned in a software development context, you may be forgiven for being in the dark on the subject. I first learned of the reactive paradigm after coming across something called the Reactive Manifesto. The manifesto, written by several Typesafe engineers in collaboration with a number of prominent figures such as Martin Thompson, Erik Meijer, and Martin Odersky (the creator of scala), describes the design pillars of reactive systems. The first version was published in July 2013 but was updated in September 2014 to reflect feedback from the community and a "simplification" of the scope and message.
So what is the reactive manifesto, and why should you care? Essentially, it describes a system design approach that lends itself well to large-scale, distributed, high-performance applications. To borrow a passage from the document itself:
Only a few years ago a large application had tens of servers, seconds of response time, hours of offline maintenance and gigabytes of data. Today applications are deployed on everything from mobile devices to cloud-based clusters running thousands of multi-core processors. Users expect millisecond response times and 100% uptime. Data is measured in Petabytes. Today's demands are simply not met by yesterday’s software architectures.
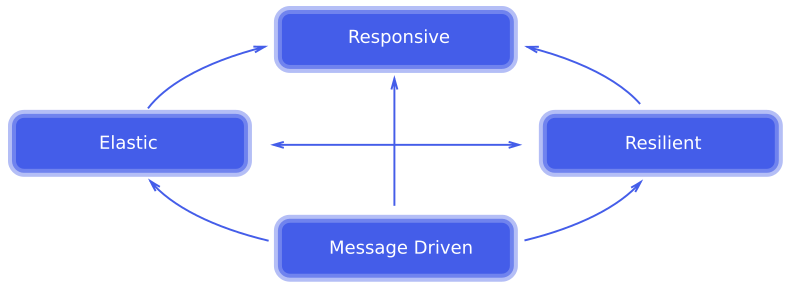
According to the manifesto, there are four key attributes that describe systems ready to meet the challenges listed above:
Responsive - The system responds in a timely manner if at all possible.
Resilient - The system stays responsive in the face of failure.
Elastic - The system stays responsive under varying workload.
Message Driven - The system relies on asynchronous message-passing to establish a boundary between components that ensures loose coupling, isolation, location transparency, and provides the means to delegate errors as messages.
I won't go into too much detail on these characteristics beyond the relatively vauge descriptions above, but the interested reader should check out the manifesto itself as well as this blog post for some background on why several attributes were changed from the original version. What I'd like to do instead is discuss how these attributes intersect with other concepts you may already be familiar with, and how these concepts allow us to implement reactive principles.
In a sense, reactive programming is simply an extension of functional programming. After all, what are the core principles of functional programming? Aside from higher-order functions, I would argue it's immutability (data structures are not modified once created), statelessness (functions have no "history" and always give the same output for a given input), and composition (functions are broken down into the smallest possible units and complex operations are built out of simpler functions in a composition chain). These same principles are the key to building distributed systems, which is what reactive programming is all about. In fact, in the Reactive Programming course offered on Coursera, the first few weeks of the course focus exclusively on functional programming. Clearly there is some conceptual overlap here.
(If you're totally unfamiliar with functional programming, this article has a nice introduction with some practical examples in Javascript)
So we've covered how functional and reactive programming are similar, but how do they differ? Why create this new "paradigm" in the first place if it's really just a re-hash of functional programming? I think there are three concepts in reactive programming that make it unique - concurrency, asychrony, and data streams. Reactive is all about managing distributed state by coordinating and orchestrating distributed data streams, and this requires both a functional approach as well as an awareness and understanding of concurrency, asychrony, and data streams. Let's break these down a bit and see how they fit into the big picture.
Concurrency is exactly what it sounds like - running operations in parallel across some system boundary. It could be across several threads running on the same processor, or it could be across several cores on the same processor, or it could be across physical computers over a network. Conceptually they're all related because they share some of the same challenges, namely resource contention and the deadlocks that can arise from an improper design.
Asynchronus computing should be familar to anyone that's done web development before. Ever registered an on-click event in jQuery? That's an asynchronous function. More generally, asynchronous operations are event-driven and non-blocking. Unlike a "traditional" computer program where each instruction is executed sequentially, an asynchronous operation is not guaranteed to be complete before the next operation begins executing. Instead, it fires an event upon completion signaling that it is done executing and its result is available for use.
Closely tied to the concept of asynchronous computing is the notion of a "future" or "promise". Going back to the previous example, if a program is executing sequentially and calls an asynchronous function, what does it get back from the function? It's not the return value because we already said the operation is non-blocking - in other words, the program doesn't wait around for the async function to finish but instead keeps going to the next operation. So if the async function doesn't yield it's final return value, what is it returning? The answer is a "future". This is a really general concept that could be implemented a lot of different ways, but essentially it's a data structure that at some point in the future will contain the return value of the async function.
Once we've got the concept of a future down, one fairly obvious question might be - what happens if there's more than one return value? This leads to the last concept - a data stream. You might see this referred to as an "observable" in some contexts. To grok the idea of a data stream, think about a stream of clicks being recorded on a website. Clicks can occur at any time and there is no "end point" after which there will be no more clicks (i.e. it goes on indefinitely). The collection of click events can be thought of as a data stream. Put another way, data streams are async collections. They are to futures as lists are to unit values in the synchronous world.
Now that we've defined these concepts, let's circle back to reactive programming. Reactive, in my view, is the amalgation of the functional concepts I described earlier with the concepts of concurrency, asychrony, and data streams. Reactive applications use all of this together to provide responsive, resilient, elastic services built on compositions of distributed micro-services interacting through immutable data streams with no shared internal state.
The observant reader may notice that I didn't mention the "message-driven" attribute. In the original version of the manifesto this was "event-driven" instead but was changed in the latest revision. I think the ideas are somewhat interchangable, the difference being that messages are more general in the sense that they may communicate things other than events. Conceptually, messages provide an asynchronous boundary that necessitates a decoupling from implementation details of the message's sender and reciever, which may be why "message-driven" was chosen instead. If we relax the definition of "message" to be understood in the general rather than literal sense, then I believe this attribute can be used to describe the conduit through which events are communicated. Under this assumption, the examples we discussed above may also be considered "message-driven".
I'm obviously just scratching the surface of this topic, and to be perfectly honest I'm still learning it myself! I'll conclude this post with some helpful resources to further pursue learning about reactive programming. I mentioned the Coursera course already, which is great if you really want to get into the nuts and bolts of reactive programming (I personally found it hard to follow but your mileage may vary). The other resources I want to mention are the ReactiveX website and the Akka library. ReactiveX is an implementation of the "observer" (data stream) pattern on most of the major computing platforms. The website contains tons of useful documentation and practical code examples. Akka is a software library written on the JVM that implements the actor model. Akka is used in a lot of large-scale distrubuted computing architectures and is worth investigating if you're serious about understanding and building reactive systems.
That concludes my primer on reactive programming! This is a fascinating subject that is almost certainly going to become more mainstream as time goes on. Hopefully this information gave you a decent introduction to the concepts behind reactive systems and spurred some interest to dive deeper and learn more about reactive programming.